This approach allows developers to plug in data structures based on the usual criteria: space/time tradeoffs, whether persistence is required, whether the data set is static or dynamic, cost, availability, etc.
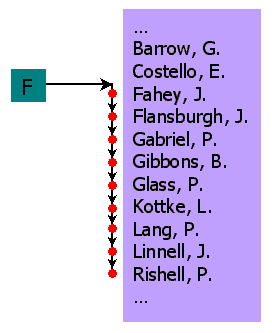
The index abstraction has functions for adding objects to and deleting objects from the index. It also includes functions for searching the index. Random access is like looking up a name in a phone book. For example, if you want to find the first name beginning with "F", (Fahey, J.) then a phone book provides the ability to do so quickly because it is organized for efficient random access. Following a random access, sequential access locates neighboring index entries, (Flansburgh, J.; Gabriel, P.; Gibbons, B., etc.).
Geophile's index abstraction is keyed by numbers, not alphanumeric information, but the ideas of random and sequential access are the same.
